Abstract:
We argue that the current model for flow establishment in the Internet: DNS Names, IP addresses, and transport ports, is inadequate due to problems that go beyond the small IPv4 address space and resulting NAT boxes. Even where global addresses exist, firewalls cannot glean enough information about a flow from packet headers, and so often err, typically by being over-conservative: disallowing flows that might otherwise be allowed. This paper presents a novel architecture, protocol design, and implementation, for flow establishment in the Internet. The architecture, called NUTSS, takes into account the combined policies of endpoints and network providers. While NUTSS borrows liberally from other proposals (URI-like naming, signaling to manage ephemeral IPv4 or IPv6 data flows), NUTSS is unique in that it couples overlay signaling with data-path signaling. NUTSS requires no changes to existing network protocols, and combined with recent NAT traversal techniques, works with IPv4 and existing NAT/firewalls. This paper describes NUTSS and shows how it satisfies a wide range of “end-middle-end” network requirements, including access control, middlebox steering, multi-homing, mobility, and protocol negotiation.
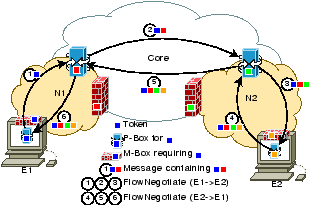
Parameters E : (user, domain, service) - Endpoint name A : address - Network address to reach endpoint P : port - Transport port for data flow τ : (token, nexthop) - address-routing state ρ : (EP, AP) - Referral to P-Box Name-routed messages (sent to P-Box) Register(E, A) Register a name-route (wildcards OK). FlowNegotiate(Esrc, Edst, Asrc, τ1…n) Use name-routed signaling to negotiate address-routed path. P-Boxes add τi, and modify Ax to effective address Ax' Address-routed messages (sent through M-Box) ρ = FlowInit(Aself, Apeer', Pself, τ1…n) Use address-routed signaling to initialize data path. An M-Box may refer to additional P-Boxes to contact M-Boxes modify Px to effective port Px' ρ = send(Aself:Pself, Apeer':Ppeer', data) Send data packet Access Control (sent to P-Box) Disallow(Edst, Esrc) Allow(Edst, Esrc) Add/remove filters for destination (wildcards OK).
Table 1: NUTSS API for establishing flows and controlling access
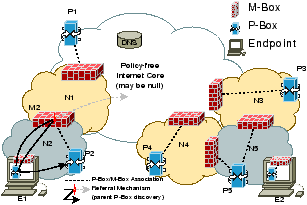
NUTSS models the Internet topology as policy-aware edge networks connected by a policy-free core (Figure 1). The policy-free core (or just core for short) is defined as the set of interconnected networks that do not assert middlebox policies and so do not deploy P-Boxes. This model reflects the current Internet: networks with firewalls today correspond to (policy-aware) edge networks, and networks without firewalls correspond to the (policy-free) core. Edge networks may comprise smaller networks that are separate administrative entities. Each network designates one logical P-Box (potentially multiple physical instances), which may be located either inside or outside that network (e.g. in the figure, network N2 designates P-Box P2 and N1 designated P1). A P-Box for a network not connected directly to the core has a parent P-Box. The parent P-Box is the P-Box for an adjacent network through which the former connects to the core (P1 is P2's parent). A P-Box for a multi-homed network (P5) has multiple parents (P3,P4).
function ProcessReigster(E,A) Requires: E is endpoint name (Eu,Ed,Es) Requires: A is next-hop address to E Requires: E has been authenticated, can be reached through A, and is authorized to register as per local policy. Ensures: Name-routed path from contact P-Box for Ed to E exists UpdateRegistrationTable(E,A) Al := GetLocalAddress() FwdTo := GetParentPBoxAddresses() if IsEmpty(FwdTo) FwdTo := GetContactPBoxAddressesFor(Ed) if Contains(FwdTo, Al) return Msg := new Register(E,Al) for Ap in FwdTo SendTo(Msg, Ap)
function ProcessFlowNegotiate(Es,Ed,As,T) Requires: Es is source endpoint Requires: Ed is destination endpoint (Edu,Edd,Eds) Requires: As is effective source address Requires: T is address-routing state {τ1…n} Requires: Es is authenticated and authorized to contact Ed Ensures: Endpoints acquire address-routing information needed if DisallowedByFilter(Ed,Es) return false if ExistsInRegistrationTable(Ed) FwdTo := RegisteredAddress(Ed) else if HaveParentPBox() FwdTo := SelectParentPBoxAddress() else FwdTo := SelectContactPBoxAddressFor(Edd) Tok := CreateAuthToken() if BehindNAT(As) or ExplicitMBox() As' := GetMBoxExternalAddress() else As' := As T' := T ∪ {(Tok,As)} Msg := new FlowNegotiate(Es,Ed,As',T') SendTo(Msg, FwdTo)
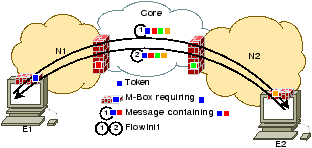
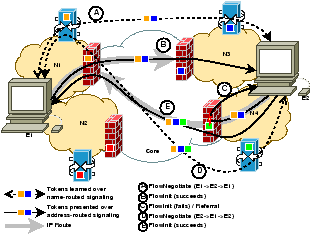
Figure 4: Flow initialization over address-routed signaling (performed after flow negotiation in Figure 3).
function ProcessPacket(P) Requires: P is an address-routed packet Ensures: Only authorized flow packets can pass if ForExistingFlow(P) or ForMyPBox(P) ForwardPacket(P) return if PacketIsFlowInit(P) for τi in P if IsValidAuthTokenForMe(τi) if IAmANAT(P) FwdTo := GetNextHopIn(τi) CreateNATState(P, FwdTo) ForwardPacket(P) return RespondWithReferral(P)
We end this section with an example that demonstrates the need to couple name-routed and address-routed signaling, and describes how existing approaches fail in this case. The example involves a scenario, shown in Figure 5, that may easily arise with site multi-homing. In this example endpoints E1 and E2 wish to communicate. Both endpoints are multi-homed; E1 connects to the Internet through networks N1 and N2, and E2 connects through N3 and N4. Each network Ni operates a NAT M-Box (Mi with external address AMi) and an associated P-Box (Pi). Inside the multi-homed networks, IP routing results in asymmetric paths — packets from E1 to AM3 and AM4 are routed through N1 and N2 respectively, while packets from E2 to AM1 and AM2 are routed through N4 and N3.
# From To Message 1. E1 P1 FlowNegotiate(E1,E2,AE1,[]) 2. P1 P3 FlowNegotiate(E1,E2,AM1,[τ1]) 3. P3 E2 FlowNegotiate(E1,E2,AM1,[τ1,τ3]) 4. E2 P3 FlowNegotiate(E2,E1,AE2,[τ1,τ3]) 5. P3 P1 FlowNegotiate(E2,E1,AM3,[τ1,τ3]) 6. P1 E1 FlowNegotiate(E2,E1,AM3,[τ1,τ3]) 7. E1 M1 FlowInit(AE1,AM3,PE1,[τ1,τ3]) 8. M1 M3 FlowInit(AM1,AM3,PM1,[τ1,τ3]) 9. M3 E2 FlowInit(AM1,AE2,PM1,[τ1,τ3]) 10. E2 M4 FlowInit(AE2,AM1,PE2,[τ1,τ3]) 11. M4 E2 Referral(P4,AP4) 12. E2 P4 FlowNegotiate(E2,E1,AE2,[τ1,τ3]) 13. P4 P1 FlowNegotiate(E2,E1,AM4,[τ1,τ3,τ4]) 14. P1 E1 FlowNegotiate(E2,E1,AM4,[τ1,τ3,τ4]) 15. E1 P1 FlowNegotiate(E1,E2,AE1,[τ1,τ3,τ4]) 16. P1 P4 FlowNegotiate(E1,E2,AM1,[τ1,τ3,τ4]) 17. P4 E2 FlowNegotiate(E1,E2,AM1,[τ1,τ3,τ4]) 18. E2 M4 FlowInit(AE2,AM1,PE2,[τ1,τ3,τ4]) 19. M4 M1 FlowInit(AM4,AM1,PM4,[τ1,τ3,τ4]) 20. M1 E1 FlowInit(AM4,AE1,PM4,[τ1,τ3,τ4])
Table 2: Message-flow for asymmetric routing example.
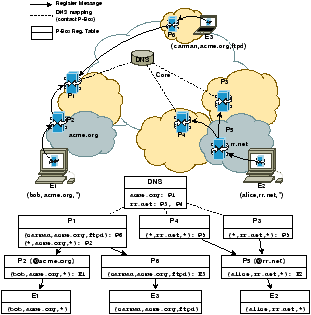
Our implementation uses SIP [44] for name-routing. While other name-routed signaling protocols (e.g. Jabber/XMPP [47]) may be used, we chose SIP because of its maturity and support in commercial hardware. At the same time, our choice allows us to assess what subset of SIP is most important for NUTSS.NUTSS name: (user,domain,service,instance)
SIP URI encoding: user@domain;srv=service;uuid=instance
Socket API NUTSS Primitive SIP Counterpart nbind Register REGISTER nsetpolicy Allow/Disallow re-REGISTER (w/ CPL) nconnect FlowNegotiate INVITE naccept FlowNegotiate 200 OK nsend/nrecv FlowInit (one-time) - nclose - BYE
Table 3: Mapping from socket operations to NUTSS primitives, and NUTSS primitives to SIP messages used.
This document was translated from LATEX by HEVEA.