Abstract:Advertising plays a vital role in supporting free websites and smartphone apps. Click-spam, i.e., fraudulent or invalid clicks on online ads where the user has no actual interest in the advertiser’s site, results in advertising revenue being misappropriated by click-spammers. While ad networks take active measures to block click-spam today, the effectiveness of these measures is largely unknown. Moreover, advertisers and third parties have no way of independently estimating or defending against click-spam.
In this paper, we take the first systematic look at click-spam. We propose the first methodology for advertisers to independently measure click-spam rates on their ads. We also develop an automated methodology for ad networks to proactively detect different simultaneous click-spam attacks. We validate both methodologies using data from major ad networks. We then conduct a large-scale measurement study of click-spam across ten major ad networks and four types of ads. In the process, we identify and perform in-depth analysis on seven ongoing click-spam attacks not blocked by major ad networks at the time of this writing. Our findings highlight the severity of the click-spam problem, especially for mobile ads.
Background and motivation: Click-spam costs online advertisers on the order of hundreds of millions of dollars each year [4]. Instead of supporting free smartphone apps and websites, this money ends up in the pocket of click-spammers. Click-spam 1 subsumes a number of scenarios that all have two things in common: (1) the advertiser is charged for a click, and (2) the user delivered to the ad’s target URL has no actual interest in being there. Click-spam can be generated using a variety of approaches, such as (i) botnets (where malware on the user’s computer clicks on ads in the background), (ii) tricking or confusing users into clicking ads (e.g., on parked domains), and (iii) directly paying users to click on ads.
Incentives for click-spam are linked directly to the flow of money in online advertising — advertisers pay ad networks for each click on their ad, and ad networks pay publishers (websites or phone apps that show ads) a fraction (typically around 70%[2]) of the revenue for each ad clicked on their website or app. A publisher stands to profit by attracting click-spam to his site/app. An advertiser stands to inflict losses on his competitor(s) by attracting click-spam to his competitors’ ads. An advertising network stands to increase revenues (but lose reputation) by not blocking click-spam.
Reputed online ad networks have in-house heuristics to detect click-spam and discount these clicks [39]. No heuristic is perfect. Advertisers pay for false negatives (click-spam missed by the heuristic). None of the ad networks we checked release any specifics about click-spam (e.g., which keywords attract click-spam, which clicks are click-spam, etc.) that would otherwise allow advertisers to optimize their campaigns, or compare ad networks.
Research goals and approach: We have two main research goals in this paper. Our primary goal is to design a methodology that enables advertisers to independently measure and compare click-spam across ad networks. The basic idea behind our approach is simple: since the user associated with click-spam is, by definition, not interested in the ad, he would be less likely to make any extra effort to reach the target website than a user legitimately interested in the ad. The advertiser can measure this difference and use it to estimate the click-spam fraction. Of course some legitimately interested users may not make the extra effort (false positives), or some uninterested users may still make the extra effort (false negatives). We correct for both types of errors by using a Bayesian framework, and by performing experiments relative to control experiments. Section 3 details our methodology.
Validating the correctness of our methodology is challenging because there is no ground truth to compare against. Ad networks do not know the false negative rate of their heuristics, and thus tend to underestimate click-spam on their network [12]. The accuracy of heuristics used by third-party analytics companies (e.g., Adometry) is unknown since their methodology and models are not open to public scrutiny; indeed, ad networks contend they overestimate click-spam [16]. We manually investigate tens of thousands of clicks we received (in Section 5). We present incontrovertible evidence of dubious behavior for around half of the search ad clicks and a third of the mobile ad clicks we suspect to be click-spam, and circumstantial evidence for the rest, thus establishing a tight margin-of-error in our methodology. In the process, we discover seven ongoing click-spam attacks not currently caught by major ad networks, which we reported to the parties concerned.
Our secondary goal is to measure the magnitude of the click-spam problem today. To this end, in Section 4, we apply our methodology to measure click-spam rates across ten major ad networks (including Google, Bing, AdMob, and Facebook) and four ad types. Our work represents the first measurement study of click-spam.
We also identify key research problems that can have a measurable impact in tackling click-spam.
Contributions: We make three main contributions in this paper. (i) We devise the first methodology that allows advertisers to independently measure and compare click-spam rates across ad networks. We validate the correctness of the methodology using real-world data. (ii) We report on the sophistication of ongoing click-spam attacks and present strategies for ad networks to mitigate them. (iii) We conduct a large-scale in-depth measurement study of click-spam today.
Search vs. contextual: Keyword-based advertising is broadly classified into two categories: (i) search advertising, which are ads based on search keywords that show up on the side of search results, and (ii) contextual advertising, which are ads that show up on Web pages or in applications based on keywords extracted from the context. Search ads may be syndicated — i.e., they are shown not only on the search engine operated by the ad network (e.g., on www.google.com), but also on affiliate websites that offer customized search engines (e.g., www.ask.com). The term publisher refers to the party that showed the ad (e.g., website for contextual ads, smartphone application for mobile ads, affiliate for syndicated search ads). We do not consider other kinds of ads (e.g., ads in videos, banner ads, etc.) in this paper.
Mobile vs. non-mobile: Both search and contextual advertising can be further classified as mobile or non-mobile based on what device the search or webpage request originated from. Mobile includes smart-phones and other mobile devices that have “full browser capabilities”, as well as feature-phones with limited WAP browsers. The reason we draw a distinction between mobile and non-mobile is because we found ad networks internally seem to have very different systems for serving the same ads to mobile vs. to non-mobile users. We do not know the reason for this difference, but speculate it is because ad networks tend to expand through mergers and acquisitions, resulting in multiple technology stacks operating concurrently.
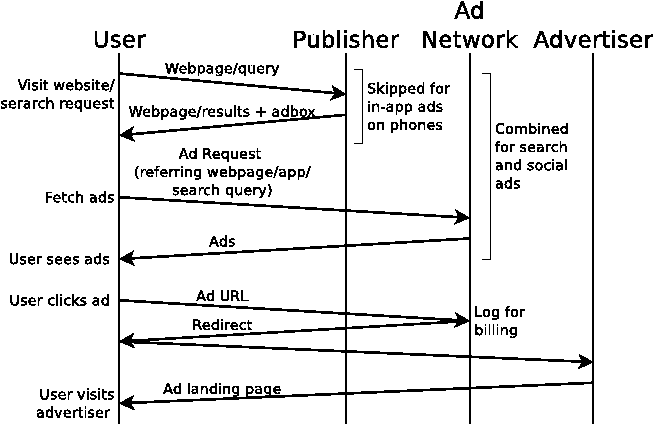
Ad delivery: Figure 1 illustrates the time-line for serving online ads. When the user visits a publisher website, the website returns an adbox (e.g., embedded iframe), which causes the user’s browser to contact the ad network. The request to the ad network identifies the referring website through the HTTP Referer (sic) header. The ad network then populates the adbox with contextual ads. In an alternate mechanism (not shown), premium publishers may directly query the ad network for relevant ads and seamlessly integrate them into the website content.
Charging model: While there are multiple charging models for online advertising (e.g., impression-based, action-based), by far the most common is pay-per-click (PPC or CPC), where the advertiser is charged (and publisher paid) only if the user clicks on the ad. The publisher gets some fraction (typically 70%) of the revenue that the ad network collects from the advertiser. The accounting is performed as follows. The ad URL points to the ad network’s domain with information about which ad was clicked (encoded in the GET parameters). When the user clicks an ad, the browser contacts the ad network, which logs the encoded information for billing purposes and redirects the user to the advertiser’s site. This redirection is typically performed through an HTTP 302 response, which preserves the publisher’s URL in the HTTP Referer seen by the advertiser’s Web server. Black-hat techniques such as Referer-Cloaking [5] by the publisher, ad network policies [14], or bugs in browsers and proxies may result in empty or bogus Referer values being sent to the advertiser.
User engagement: The ad network can track limited user engagement (i.e., ads viewed or clicked) for multiple ads shown across multiple publishers (e.g., using cookies), but cannot, in general, track user engagement after the click. The advertiser, on the other hand, can track detailed user actions (only) on the advertiser’s own website, but cannot track user engagement with other ads. Thus while the ad network has a broad-but-shallow view, the advertiser has a narrow-but-deep view into user engagement.
Click-spam discounts: Ad networks internally discount clicks based on in-house heuristics. The user is still redirected to the advertiser, but the advertiser is not charged for the click. Ad networks do not indicate which clicks were charged and which not in the advertiser’s billing report.
In this section we design a method that any party (e.g., advertisers, ad agency, or researchers) can use to estimate click-spam rates for a given ad without explicit cooperation from the ad network.
No ground truth: It is not possible to first identify (definitively) which clicks are click-spam, and then compute what fraction of the total traffic click-spam accounts for. A click is click-spam if the user did not intend to click the ad. There is no way to conclusively determine user intent without explicitly asking the user.
No global view: As mentioned, the ad network cannot track user engagement on the advertiser site, and the advertiser has no knowledge of the user’s engagement with other advertisers. For example, the ad network does not know if the user never loads the advertiser’s site after the click (we saw botnets exhibiting this behavior), and the advertiser does not know if the same user is implicated in click-spam attacks on another advertiser. The obvious solution is for the ad network and advertiser to cooperate. But financial disincentives and legal concerns prevent them from doing so: the advertiser could lie in his favor (claiming fraud where there is none) in order to gain deeper discounts from the ad network; the ad network could be held liable if sharing user history with advertisers has unforeseen privacy consequences.
Granularity: The granularity over which click-spam is estimated is important. An ad network may have low click-spam overall, say, but certain lucrative segments (e.g., mortgage) may be experiencing orders of magnitude more click-spam. Advertisers require fine-grained measurements for their selected set of keywords.
Noise: As in any Internet-scale system, data is extremely noisy. We encountered users where Referer headers are inexplicably omitted, or browser User-Agents, IP addresses, cookies etc. change inexplicably within the same session (perhaps a buggy browser or proxy), and bad publishers that behave non-deterministically (perhaps to avoid detection). At the same time, because clicking an ad is a rare event, gathering good data is time-consuming. The combination results in very low signal-to-noise ratios.
We apply a Bayesian approach to work around the lack of ground truth. Instead of attempting to conclusively identify which clicks are click-spam, for a given ad, we create two scenarios detailed below where the (unknown) fractions of click-spam traffic is different. We link the two using a Bayesian formula to effectively cancel out quantities we cannot measure. The remaining quantities are those an advertiser can measure locally without requiring a global view. We control for noisy data (i.e., adjust for false-positives and false-negatives) using a control experiment. Our approach does not (and indeed cannot) report whether a specific click is click-spam or not. The output is a single number representing our estimate of the fraction of clicks for the given ad that click-spam accounts for.
The detailed data collection procedure is as follows.
Assumption 1. An implicit assumption is that the interstitial page will turn away a (unknown) larger portion of the click-spam traffic than the (unknown) portion of legitimate traffic it turns away. Specifically, we do not assume for example that all good users will patiently wait a few seconds; rather we assume that a smaller portion of click-spam traffic will wait the duration than the portion of good users doing so. Indeed user dwell time and willingness to click have long been considered an implicit measure of user interest [29, 35]. Interstitial pages leverage this knowledge to enhance the quality of the traffic reaching the landing-page by some (unknown) amount as compared to without the interstitial page.
Assumption 2. We make an implicit assumption that for users that are not turned away by the interstitial page, their likelihood of becoming gold-standard users is not significantly changed. We do not assume that the interstitial page will not turn away users who may have become gold-standard users. Rather we assume for example that some users will not wait on the interstitial page, but if they do, they will not hold a grudge. We empirically find this assumption to hold in practice as we report later.
Assumption 3. We assume that very few users will intentionally click the second ad. While some users may be curious about the random set of words, we find this assumption is borne out in practice. We also assume for now that the click-spam click-through-ratio i.e., the ratio of click-spam clicks to impressions of the ad) is independent of the text of the ad (we relax this assumption later).
Let Gd and Gi be the event that the user is a gold-standard user that arrived either directly, or via the interstitial page respectively. Let Id and Ii be the event that the user intended to click the ad (i.e., not click-spam) out of all users directly reaching the landing-page, or all users reaching via the interstitial page respectively.
Bayesian equation for P(Id): The advertiser is interested in learning P(Id). G and I are linked using Bayes theorem as follows: P(G|I) = P(I|G) × P(G) / P(I). Note that a gold-standard user implies that the click is not click-spam, i.e., P(I|G) = 1. As discussed above in Assumption 2, P(Gd|Id) ≃ P(Gi|Ii); substituting and simplifying yields: P(Id) = P(Gd) × P(Ii)/P(Gi).
P(G) is computed as the ratio of the number of gold-standard clicks (g; known) to the number of clicks (n; known). P(Ii) is the ratio of the number of non-click-spam clicks (ii; unknown) to the number of clicks (ni; known) arriving via the interstitial page. The above equation reduces to:
| P(Id) = |
| = |
| (1) |
Only ii on the right-hand-side is unknown.
Estimating ii: As mentioned, the interstitial page enhances the traffic quality. If it did a perfect job — i.e., all unintentional clicks would be turned away, and all intentional clicks would pass through — computing ii would be trivial. In practice, the interstitial page has false-negatives (turns away users intentionally clicking the ad) and false-positives (not turning away click-spam). False-negatives do not affect ii since it is the number of non-click-spam clicks actually reaching the landing-page, but false-positives result in an inflated value of ii. We use a control ad to estimate the number of false-positives, and adjust for it.
Let Fi and Ti be the false-positive and true-positive click-through-ratios for the original ad and the interstitial page i. Similarly, let F′i and T′i be the false- and true-positive click-through-ratios for the control ad (identical ad except with junk ad text as mentioned above). We have four unknowns, and need four equations to solve. As discussed above in Assumption 3, we assume T′i ≃ 0 and Fi = F′i. The advertiser can measure Fi + Ti = li/d where li is the number of clicks for original ad reaching the landing page through the interstitial page, and d is the number of impressions of the original ad as reported by the ad network, and the corresponding equation F′i + T′i = l′i/d′ for the control ad.
The estimate for ii is simply Ti × d. Solving the four equations above for Ti we get the value of ii adjusted downwards to account for false-positives as: ii = li − l′i × d/d′
Final estimation formula: Combining the above with Eq. (1) we can estimate the click-spam rate for the original ad as:
| P(Id) = |
| (2) |
| where: | |||
| gd, gi | : | numbers of gold-standard users arriving directly and | |
| through the interstitial page respectively | |||
| d, d′ | : | number of impressions of the original ad and control | |
| ad respectively | |||
| li, l′i | : | number of clicks reaching (via the interstitial page) | |
| the landing-page for the original ad and control ad | |||
| respectively | |||
| nd | : | number of clicks on the original ad directly reaching | |
| the landing-page |
All these quantities can either be measured directly by the advertiser, or are present in billing reports ad networks generate today.
A key limitation of our approach is that the advertiser must actively measure click-spam. The advertiser must interpose the interstitial page on live traffic (that he has paid-for), create a control ad (that he needs to pay for) to correct for false-positives, etc. Both the interstitial ad and control ad harm the user experience. It would be far more desirable to be able to passively look at logs and be able to estimate the click-spam rate from them.
One way to minimize the user experience impact is to apply our approach reactively when click-spam is suspected, but that runs into a second limitation — the rarity of data. Any estimation technique requires statistically significant data. The crucial factor in Eq. (2) is gi and gd — the number of gold-standard users. If these are small, the click-spam estimate can swing wildly. Suppose the advertiser manages to identify two gold-standard users, one arriving through the interstitial page and one directly, and computes a click-spam estimate based on it. If one new gold-standard user arrives through the interstitial site (or directly), the new click-spam estimate is half the previous (or will double). For a statistically significant estimate, as we report later, the advertiser must wait for roughly 25 gold-standard users via the two paths. This is especially an issue for small advertisers. Small advertisers may have to wait a long time to get gold-standard users — low advertising budgets means their ads don’t get shown as much, even if they get shown users may not click on poorly ranked ads, even if they click they may not engage in a financial transaction with the advertiser, etc. The need to gather data over such an extended period is clearly at odds with minimizing the impact on user experience.
A group of small advertisers targeting similar keywords/users (or an ad-agency representing them) can apply our approach in the aggregate. Doing so has two benefits. First, due to the aggregation effect the group accretes statistically significant data more quickly. And second, the user experience impact is amortized across many advertisers. The downside, however, is that advertisers lose the ability to individually define what a gold-standard user means (which our approach otherwise allows) and have to depend on someone other than themselves to estimate click-spam rates.
Finally, our approach is naturally sensitive to the three choices the advertiser needs to make: 1) what his definition of a gold-standard user is, 2) what interstitial page approach he wishes to use, and 3) what the text of the control ad is. We discuss the implication of each design decision in turn. First, if the advertiser sets too high a bar for the gold-standard user he may not get statistically significant data; if he sets too low a bar that even click-spam users get classified as gold-standard he will underestimate click-spam rates. Second, if the advertiser picks too easy an interstitial page (everyone gets through), in Eq. (2) gd/gi will approach nd/li and the estimate will approach 1 (i.e., all clicks are legitimate) if the advertiser doesn’t use a control ad; or 0 if he uses a control ad (i.e., no clicks are valid). If the advertiser picks too hard an interstitial page (no one gets through), gi and li will both approach 0, and the click-spam estimate will become undefined. Thus there is clearly some sweet-spot in designing the interstitial page, which we do not discuss. Third, if the control ad is not independent of the original ad (e.g., the random choice of words happens to be related to the original ad), false-positives may be over- or under- corrected for. Making the right design choices is advertiser-specific.
To address the above issues to some degree, we report in the next section our experience with multiple types of interstitial pages, different definitions and numbers of gold-standard users. While our data shows much promise in our approach, we stress that a more thorough evaluation is needed.
In this section we first validate the correctness of our approach from the previous section. We then conduct a large-scale measurement study of ten major ad networks and four types of ads.
Validation strategy: We assume that reputed search ad networks (specifically Google and Bing) are mature enough that their in-house algorithms are able to detect and discount for most of the click-spam on their search affiliate network. Validating our measurement approach then involves computing our click-spam estimate and comparing it to the charged clicks for Google and Bing search ads. Note that our algorithm does not have access to any data (including historical and aggregate data) that in-house algorithms at Google and Bing have access to, and Google and Bing do not have access to the detailed user-engagement data we collect as advertisers for user clicking our ads (specifically, we do not use any of the analytics products offered by Google or Bing). Given the datasets are completely different, if the click-spam rates we compute match that computed by leading ad networks (which they do as we report below), we have a strong reason to believe that our measurement approach is sound.
We sign-up with ad networks as three different advertisers (each targeting different keywords) and follow the methodology from the previous section. The first advertiser targets a highly popular keyword (celebrity). The second, a medium-popularity keyword (yoga). And the third, a low-popularity keyword (lawnmower). We pick the keywords from a ranked list of popular keywords that the advertising tools of these ad networks provide.
For each keyword we create a realistic looking landing page, since the policies of the ad networks require us to use keywords that are relevant to the landing page. We instrument the landing-page to track mouse-movement, time spent on the page, switching browser tabs into or away from our page, whether any link on the page was clicked or not, page scroll, etc. Our instrumentation is through Javascript on the page; we detect browsers that don’t support Javascript or have it disabled and exclude those data points. We direct on-path proxies (if any) to not cache any response so our server logs accurately reflect accesses. Unless otherwise mentioned, we pick a lax definition of gold-standard users based on this telemetry, which is, that the user stays on the page for at least five seconds, and (for non-mobile browsers) produces at least one mouse/cursor move event. We are unable to define gold-standard users based on financial transactions, even though we expect that to be very strong signal of intent for real advertisers.
Next we create three interstitial pages: the first shows a loading message for five seconds before automatically redirecting to the landing-page. The second asks the user to click a link to continue to the landing-page. And the third asks the user to solve a CAPTCHA. We do not test the CAPTCHA interstitial for Google traffic since their advertiser policies restrict us from doing so.
We then create four ads for each target landing-page. The first ad directly takes the user to the landing page. The second, third and fourth ads first take the user to the three interstitial pages respectively, before continuing on to the landing page. All ads target the same keyword(s), user demographics, device and platform types, etc. The reason we create four separate ads (instead of a single one and interposing the interstitial page after the click) is so that Google/Bing produce fine-grained billing reports and statistics for each ad, which we can then validate our design choices against.
We create four additional (control) ads for each landing-page that correspond to the four original ads, but with junk ad text. The ad text was generated by picking five random words from an English dictionary (e.g., Figure 2).
We repeat the above for 10 ad networks. For search ads we measure Google Search, Bing Search, and 7Search. For contextual ads we measure Google AdSense and Bing Contextual. For mobile ads we measure Google Mobile, Bing Mobile, AdMob (now owned by Google), and InMobi. And lastly for social ads, we measure Facebook. Altogether this adds up to 216 ads across all the networks.
We run the ads for a period of 50 days as needed to gather enough data. The majority of the ads were flighted in early January 2012. We continually adjust bids (mostly revising them higher) to help the lower popularity ads quickly attract enough data.
In all our ads were shown 26M times across all ad networks. They resulted in a total of 85K clicks (17K charged). Our ads were shown at at-least 1811 publisher websites and mobile apps (but the true number is likely much higher since we cannot determine the publisher for over 65% of our traffic). The landing pages were fetched by a total of 33K unique IP addresses located in 190 countries. We encountered over 7200 browser User-Agent strings (after sanitizing them to remove browser plugin version numbers).
We log all web requests made to our server. The logs used in this study are standard Apache webserver logs that include the user’s IP address, date and time of access, URL accessed (of a page on our webserver) along with any GET parameters, the HTTP Referer value and User-Agent value sent for that request, and a cookie value we set the first time we see a user to identify repeat visits from the same user. The raw logs including user engagement telemetry weighs in at over 3 GB.
A sanitized version of our raw logs is available online2.
Throughout our study we followed the advertiser terms-of-service (current as of when we did the measurement) for each of the ad networks we measured. Whenever our ads were rejected by the ad network (due to policy reasons) we fixed the issue so as to be compliant; if we couldn’t fix it, we simply dropped that data-point.
High click-spam is an embarrassment for ad networks. Our goal in this paper is to systematically design a methodology, highlight the severity of the click-spam problem, and give researchers the tools and knowledge to further the state of the art. Our goal is not to embarrass ad networks. As a result, we prefer to report normalized or relative numbers whenever possible, and anonymize ad network names whenever it does not affect the core message of this paper.
Lastly, we expressly try to minimize adversely impacting user experience on these ad networks. For example, in order to get enough clicks on an ad, we have two options: run the campaign for longer, or increase the bid amount. We always choose the latter to minimize the time our ad is active on the network. For ads where despite increasing the bid we cannot gather traffic fast enough, we prefer to give up on that data-point and stop running that ad. Minimizing the time our ads are active also minimizes our contribution to the existing auction volatility for the keywords we bid on. As of this writing we have not received any complaints from ad networks, users, or advertisers regarding our study.
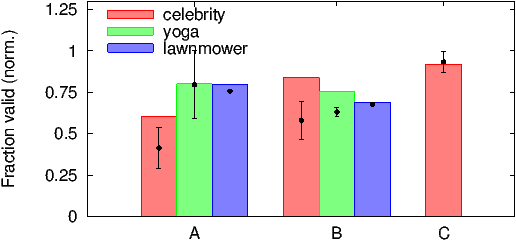
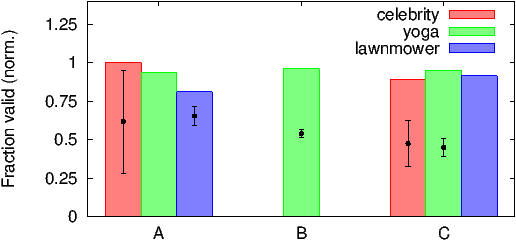
Figure 3 compares (normalized) complementary click-spam rates computed by our approach (plotted as error bars) and the (normalized) complementary click-spam rates as reported by Bing and Google for their search ad networks (plotted as bars). We ran another experiment where where we explicitly set our ad campaign to exclude syndicated search partners for one of the search ad networks (plotted as C in Figure 3). The Bing and Google estimates are the ratio between the number of clicks we were charged for (from the billing report), and the total number of landing-page fetches (from our logs). For our approach, we calculate two separate estimates based on the delay and click interstitial pages. The spread of the error bar plots the max and the min of the estimates we compute. The center tick plots the average. The figure plots the estimates for all three ads we flighted. In line with our goals, this figure (and all other figures in this section) are normalized so one of the data points is 1.
As is evident from Figure 3, our estimate for the yoga and lawnmower ads are in the same ball-park as that reported by Google and Bing. We manually investigated the difference between our estimates and that for the celebrity ad. We found over 50 clicks from sites associated with well-known search redirection viruses where browser toolbars hijack normal user searches and funnel them through affiliate search programs (Section 5.3.1 has more details). We were charged for at least 48 of these clicks. Our estimates match the search ad network’s estimates recomputed after discounting these clicks. Furthermore, as seen for network C where syndicated search partners are excluded, our estimates closely match that reported by the network. There were no clicks on the control ads on network C, which further supports our high estimate.
Our absolute numbers also agree with public estimates of average click-spam for these networks [3]. Next we drill deeper to validate our design decisions.
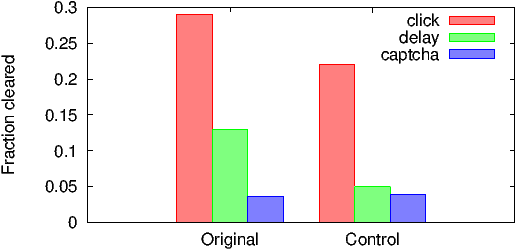
Figure 4a plots the fraction of clicks for each interstitial page that reach the landing page for the celebrity ad, and for the corresponding control ad. Note that this fraction drops as the interstitial page changes from clicking a link (29%), to waiting 5 seconds (13%), to solving a CAPTCHA (4%), demonstrating the increasingly higher bar set by the interstitial pages. Interestingly, we find users are more likely to click through to the landing-page than wait 5 seconds. Except for the CAPTCHA interstitial, the fraction reaching the landing page is significantly lower for the control ad than for the original ad; this validates Assumption 1 from the previous section that the interstitial page concentrates non-click-spam traffic (by some unknown amount). Despite the varied interstitial page performance, the estimates computed from the delay and click interstitial converge (in Figure 3) for the experiments where we have a balanced number of converters through the interstitial and direct path, which supports Assumption 2. The CAPTCHA seems to reduce both normal and control traffic to the same low base level regardless of user intent; as a result, it is unsuitable for use in our framework.
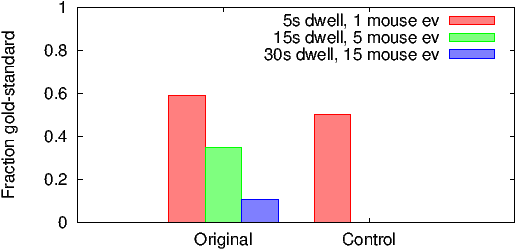
Figure 4b plots the fraction of gold-standard users for the original celebrity ad and the control ad, for three different definitions of gold-standard users. The first definition is, as before, 5s of dwell time and 1 mouse event. The second definition is 15s of dwell time and 5 mouse events. The third definition is 30s of dwell time and 15 mouse events. Note that the fraction of gold-standard users for the control ad is zero for the second and third definition. This validates Assumption 3 that very few users are curious enough to click the control ad. In a real-world setting, we expect advertisers to define gold-standard users based on financial transactions (much tighter than any of our definitions).
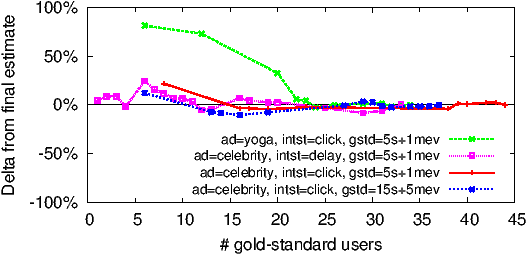
We focus next on the sensitivity of the click-spam estimate to the number of gold-standard users. Figure 4c plots the convergence of our click-spam estimate as a function of the number of gold-standard users for various combinations of our ad, interstitial page, and definition of gold-standard user. X-values are driven by the periodicity of ad network reports. Y-values are deltas from our best estimate (last data-point for that series). In each case our estimate converges at or before 25 gold-standard users.
Figure 3 shows that while reputed search ad networks generally have a good handle on click-spam, a single average click-spam metric across the entire network is of little use due to different keywords experiencing different levels of click-spam. An advertiser cares only about click-spam rates for keywords he is interested in bidding on. The difference in click-spam rates between the celebrity ad and lawnmower ad is up to 20% (normalized).
We omit discussion of 7Search since we did not get any gold-standard users through that network to base our estimates on.
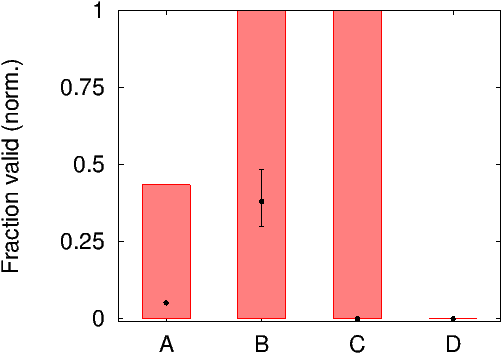
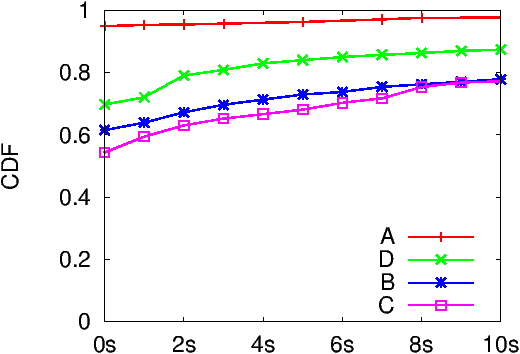
Figure 5a plots our click-spam estimates and the networks’ own estimates for the celebrity ad across the four mobile ad networks we measured. Despite running our ads for over a month, and weakening our definition of gold-standard users to only 5s of dwell time (i.e., user spent 5s on our landing page; no tap event required), we failed to attract even five gold-standard users for the yoga and lawnmower ads, and attracted fewer than twenty for the celebrity ad. While, our estimates are below the convergence threshold, to investigate the huge difference in our interim estimates and ad network numbers, we plot the CDF of user dwell-time in Figure 5b.
Ad network A charged us for over a third of the clicks (non-normalized), yet as illustrated by the y-intercept in Figure 5b, over 95% of network A users spent under a second on our landing-page! We find evidence of an attack that would result in such a signature in Section 5.4.1. Network D appears to be quite well aware of the poor traffic quality on their network; they charged us for less than 1% of the clicks. Mobile ad network C is a curious case. There is practically no difference between the click-through-rate (CTR) of our original ad and the CTR of our control ad with junk text, suggesting that the content of the ad is irrelevant for users clicking ads on this network. Our Bayesian formula understandably estimates click-spam to be nearly 100% for this network despite the network charging us for most of these clicks.
Our data, although inconclusive, suggests that charges on mobile ad networks do not currently reflect actual user intent.
Figure 6 plots our click-spam estimates, and those reported by contextual and social ad networks we measured. Network B approved only our yoga ad. Click-spam is uniformly higher than that on reputed search ad networks (not apparent due to normalization). The networks do a better job than mobile ad networks in tracking this higher rate of click-spam. Nevertheless, our estimates are uniformly lower than the numbers reported suggesting that these networks do not yet discount all click-spam. Interestingly, network B consistently charged us for more unique clicks than we logged on our server. We speculate network B does not follow the standard practice of suppressing duplicate/double-clicks by a user [39].
Recall in previous sections we assumed that very few people would intentionally click on our control ads (e.g., Figure 2), and substantiated the assumption through the lack of gold-standard users for these ads. Nevertheless, convincing ad networks requires incontrovertible evidence of fraud. One needs to discover the full sequence of events that culminate in the fraudulent click. We manually investigate clicks we receive on control ads. The sophistication and diversity of attacks makes this non-trivial. In this section we describe seven ongoing click-spam attacks we discovered.
We were charged approximately $1000 for about 30,000 clicks on all the control ads we created across all ad networks. Our investigations cover 26% of the traffic our control ads attracted on reputed networks; as expected by design, all these clicks were found to be fraudulent in nature. The ad networks typically discounted substantially less than this fraction (between 6–20%). Thus we can confidently claim that some of this fraudulent traffic is currently not caught by ad networks. Note that 26% covers only the traffic we actually investigated; we expect the disparity in discounts vs. fraudulent traffic to grow as we investigate more clicks. That being said, our manual approach is too laborious and not scalable. More automated methods for investigating click-spam are needed.
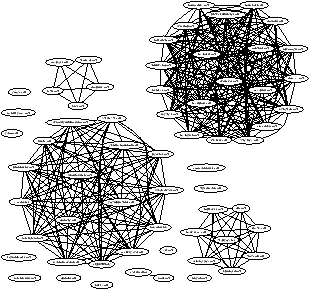
(a) Clusters (search)
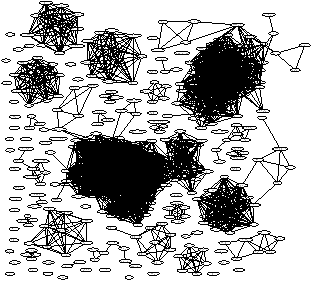
(b) Clusters (mobile)
(c) Top 5 heavy-hitter cluster for search ads
Search Cluster Signature Type % thespecialsearch.com + 2 Malware, Affiliates 5% scour.com + 3 Badware, Affiliates 14% Sedo-parked (58+) Parked Domain (cloaked) NS-parked (51+) Parked Domain 6% dotellall.com + 20 Arbitrage 18% Figure 8: Graph-clustering and heavy-hitter detection output
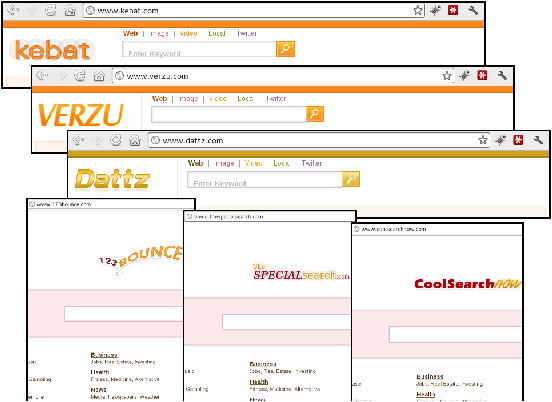
To prioritize manual investigation of the large number of clicks, we use simple graph-clustering over features in the HTTP request, and detecting heavy-hitting clusters. A naïve approach would be to use the HTTP Referer domain. We found groups of websites on unrelated domains but with nearly-identical layouts (Figure 7), all driving click-spam traffic to our site. This is done presumably to spread out the click-spam through multiple sources in order to operate below detection-thresholds of existing ad networks. Using additional features to cluster such publishers allows us to aggregate them back together and do proper heavy-hitter accounting.
Graph-clustering: We induce a graph that spans all publisher domains we see. We do this as follows. For any pair of publishers, we compute a similarity score. We construct a feature vector that consists of various network-level attributes (e.g., Web host IP address, subnet, hosting provider, domain registrar, whois information) as well as HTTP-level attributes in our logs. We assign a weight to each attribute and compute a cosine similarity between the feature vectors of the pair of domains. The similarity score ranges between 1 (identical) and 0 (dissimilar). We add a graph edge between the domains if the similarity score is above some threshold. We find this simple technique is surprisingly robust to our selection of weights and thresholds. In our data distinct cliques emerge at thresholds as low as 0.2 and stay intact beyond 0.9, thus giving us much wiggle room in picking the initial weights and thresholds (which we manually refine iteratively).
Heavy-hitter detection: We use a conductance metric to detect heavy-hitters especially when the clusters do not neatly fall out as distinct cliques. Each node in the graph shares responsibility for clicks originating from another node up to 2-hops away. We found 2-hops to be quite effective since the 1-hop neighborhood was too sparse (due to sparsity in the underlying data), and 3-hop neighborhood resulted in clusters too large for them to represent real-world collusion between bad domains. We compute a badness score for each node as the number of clicks originating in their 2-hop neighborhood. We then partition the graph into disjoint clusters by considering nodes in decreasing order of badness as cluster centers, and collapsing nodes within 2-hops from it into its cluster.
We believe better techniques based on learning and mining literature can be designed to find patterns in click-spam data (e.g., [17, 18, 22]). We leave this for future investigations both by us and other researchers. To this end, as mentioned earlier, our raw logs are available online for other researchers to use.
That being said, even our simple technique was able to find meaningful clusters. Figure 8a plots our clustering and heavy-hitter output applied to control ad clicks on Google’s and Bing’s syndicated search ad networks; all clusters also happen to be cliques. Figure 8c lists the top 5 heavy-hitter clusters. Figure 8b plots the clusters from control ads on mobile ad networks. Next, we dig deeper and discuss some case studies chosen specifically to depict the wide variety and sophistication in current click-spam techniques.
Click-spam we observed in search ads can be attributed to three main attack vectors: (1) malware and badware, (2) parked domains, and (3) arbitrage.
thespecialsearch.com affiliates: We noticed a large number of clicks in our logs that fit the pattern clicks.thespecialsearch .com/xtr_new?q=…. What followed the q= parameter changed from click to click, but almost always was a simple combination of English words (e.g., Team Building or Saving more). 5% of the search clicks in our logs matched this pattern.
Searching online we found malware reports [11] for the Win32/Olmarik (aka TDSS, TDL) botnet that had been observed fetching URLs fitting the above pattern. This particular malware family is incredibly sophisticated [23]. The malware is a generic task execution platform — it contacts its command-and-control server (C&C), downloads an arbitrary task meant specifically for that infection instance, executes it, and repeats the process. The malware hooks into all popular browsers (IE, Firefox, Safari, Chrome), through which it can inject clicks that appear indistinguishable from normal traffic generated by these browsers. The malware can also inject malicious code into iframes the user is browsing, or modify search results before they are shown to the user. It even attempts to cleanse the infected host of other malware so it has sole control over the host (and to disrupt other competing botnets).
We found a copy of the malware binary and installed it in a virtual machine. We routed all traffic from the virtual machine through a transparent proxy (running on the VM host) and logged all traffic. We configured the proxy to block SMTP traffic to block malware-generated spam campaigns. We also apply a strict network rate-limit to prevent DoS attacks, and configured our proxy to block requests to the click URL of Google, Bing, and other major ad networks to prevent advertisers being charged for clicks made by the malware instance.
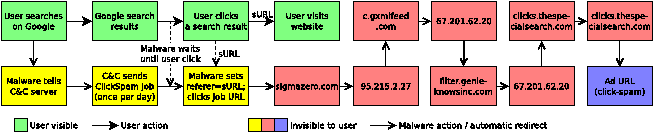
How it works: Figure 9 illustrates the process.
It is important to note that the bot did not immediately perform the click after receiving the XML file.
Note: From the user’s perspective the malware is completely transparent. The user’s search results and subsequent click were not tampered with. The user wasn’t shown any extra ads or popups. The user wasn’t redirected to an advertiser etc. The malware performed all its activity stealthily in the background.
When we acquired a new external IP address (easy to do since the ISP uses DHCP), the bot came out of dormancy, performed one click, and resumed dormancy.
Discussion: It is clear that the C&C server is tracking which bots are active and from where, and ensuring that across the botnet each IP address is used only for one click in a 24 hour period — an extremely low threshold that would likely not raise any flags. Furthermore, when the bot does click, it is gated by a legitimate user click (on the search page), which would defeat click-spam detection mechanisms that look for deviations from normal user behavior (e.g., [35]). Lastly, since it hooks into a regular browser, and forges the referer of a legitimate site, click-spam detection techniques that look for deviation at the HTTP or HTML layer would fail.
Who made money: The penultimate website (thespecialsearch.com) made money from the ad network. Note this website also shows up in our list of Sybils (Figure 7). The long chain of redirects to thespecialsearch.com presumably identify the chain of affiliates, each making some fraction of the money the next one in the chain did. We noted that the malware used different affiliate chains based on geography (i.e., it used one when in the US, and a different one when in another country). This suggests that the same malware is performing click-fraud for different “customers”. Thus the botmaster controlling the botnet likely made money as well.
scour.com affiliates: A large number of clicks were through clicks.scour.com. Scour is a meta-search engine that aggregates results from Google, Yahoo, Bing into a single search result page. It pays users to search through it, and to vote or comment on individual results. It has an affiliate program where registered affiliates are paid for users they refer to Scour.
How it works: We found a browser toolbar that hijacks the user’s searches through Scour (but doesn’t automatically click on ads.) The affiliate ID (6678) is hardcoded in the scour.com URL the toolbar points the browser to. The same affiliate ID shows up in our logs. The toolbar, which many anti-virus companies classify as the Scour redirect virus, is extremely hard to remove [9]. Additional search redirect viruses (unrelated to Scour) that we see clicks from include search-results.com, mywebsearch.com, search.babylon.com, search.alot.com and search.conduit.com. These sites explain the discrepancy between our estimate in Figure 3 and the ad networks’.
Who made money: As before, the publisher (scour.com) made money from the ad network, and the affiliate presumably made some fraction of that from Scour.
sedo.com parkers: While investigating a set of about 35 clicks from a particular domain registered by Sedo, a domain registrar, we stumbled across 57 other domains also hosted by Sedo and in our various logs. All these domains are parked domains. A parked domain is a domain name that is registered, but not in use. The registrar typically points DNS for that domain name to a Web server that serves up a “This site is under construction” or similar message, followed by a set of ads that the user may or may not click.
For these specific parked domains, however, Sedo would automatically redirect the browser to the ad click URL.
How it works:
In other cases where the owner was using the domain but is no longer, links to the domain when it was active may have been posted on forums, exchanged in emails, indexed by search engines etc., and users may click on these links in the present. There are also reports of adult link-exchange networks that launder traffic through parked domains [13].
Based on the referrer we see in our logs (which appears to be a search query on Scour) we found that the domain of the Sedo parked page is linked to the search query on Scour. For example, the publisher URL for ad clicks originating at icicbank.com is ….scour.com?q=icic+bank. Indeed this is how we discovered the set of 58 domains that auto-redirect users. For each Scour query in our logs we attempted to guess the Sedo parked domain by appending common top-level domains (.com, .net, etc.), and checking which were parked, and then determined which countries they auto-redirect for using PlanetLab nodes located in 45 countries.
The ultimate ad URL in these cases is encoded in each of the intermediate redirects starting from the very first redirect initiated at the Sedo parked domain. Thus the decision for which ad to click was made right at the onset.
Discussion: Since Sedo parked domains redirect via a chain of affiliates, detecting Sedo (or the Sedo customer) as the root-cause requires reverse-engineering the chain (in this case through a query parameter on scour.com, which taken out of context appears to be a normal search query). More deviously, the user (e.g., that typed icicbank.com) would engage normally with icicibank.com since he anyway meant to type the latter. Thus any advertiser driven engagement metrics would appear perfectly normal. Discovering such patterns automatically is likely to be highly challenging, but would illuminate a fraction of click-spam that is virtually undetectable. Detection is only part of the problem however.
Sedo is benefiting from a ad network policy that does not forbid its mode of operation. Parked domains are not only allowed to show ads, ad networks expose special APIs to help them in doing so [7]. Worse, even though ad networks have mechanisms to allow advertisers to block certain classes of traffic (e.g., traffic through proxy-servers), ad networks do not allow advertisers to block traffic from parked domains.
Who made money: thespecialsearch.com and scour.com made money from major ad networks, some fraction of which, as before, traveled through the affiliate chain to the Sedo parked page.
networksolutions.com: NetworkSolutions, another domain registrar, has a similar model as Sedo, but does not automatically redirect. They account for 6% of the clicks we see for control ads.
In one scenario we found that even though the owner of www.noblenet.org (a library website) is actively using it, NetworkSolutions is showing a parked page for noblenet.org that, at first glance, appears to be a library page except all links are ads that direct the user away from their intended URL. Note that here the user did not make a typo; he simply omitted the www, which is often acceptable.
Discussion: As before, this is largely a policy issue. Major ad network policies for parked domain affiliates states that they must not violate trademarks and copyrights [1]. NetworkSolutions does reserve for themselves the right to served parked pages for a domain (or sub-domain) in its terms-of-service (TOS) that customers must agree to. It is unclear whether benefiting from someone else’s domain constitutes copyright or trademark infringement, and if it does, whether it can be overridden by the TOS. This is a loop-hole NetworkSolutions benefits from.
Who made money: NetworkSolutions made money from major ad networks if the user clicked a link on the parked domain.
dotellall.com family: We next focus on the cluster of dotellall.com and 20 other related domains that account for 18% of the traffic for our search control ads. The entire cluster of websites on the surface appear to be lively social question answer forums (users ask questions, and post answers), but when we posted questions and answers on one of the sites, it disappeared after a few days, and the site was restored to its pristine condition. We noticed that over time the questions and answers do not change. No question has the date/time when it was asked or answered. For one of the sites, we found the content was blatantly copied from other locations on the web. As best as we can tell, the entire family of sites is an incredibly elaborate (and realistic) sham.
It was extremely puzzling as to how they attract traffic. Clearly users wouldn’t frequent a fake social site. We couldn’t find links to malware. The sites weren’t typos of other popular sites (although one is named livingfrugal.com, which is similar to the popular livingsocial.com). Confusing us further, we (initially) couldn’t find ads on their pages. It took us a long time (and a considerable amount of serendipity) to determine how this family of sites makes money.
How it works:
This suggests that they likely bid mere pennies for these thousands of ads, but nevertheless manage to acquire long-tail traffic.
This second set of ads is from a different major search ad network. Based on the keywords highlighted, we believe this second set of ads are more expensive. The site filter-ins these higher-value ads by stuffing keywords into the ad request.
Thus the family of sites acts as an advertiser with one search/contextual ad network, and as a publisher with another search ad network.
Discussion: Arbitrage has been long known to be an issue in ad networks [24]. However, such elaborate fake sites can be incredibly hard for a human at an ad network to detect (given limited time to investigate publishers). Recall how the site does not even show ads if navigated to directly. Discovery is only half the problem.
The second half is that these sites are not violating ad network policy. An advertiser may show ads on the landing-page. A publisher may advertise his site. A publisher may provide useful content hints in the ad request. A poor quality page and a prominent ad box is bad user-experience, and an SEO optimized publisher ultimately costs the advertiser, but does not violate current policy.
Who made money: The dotellall.com family of sites likely made a lot of money from one search ad network, for inexpensive traffic it bought from the other ad network.
We next turn our attention to mobile ads, which as we found in Section 4, are challenging even for reputable ad networks to detect click-spam in. Figure 8b pictorially shows why. First, because mobile advertising is a relatively new market, large legitimate content providers have not yet replaced fly-by-night operators that exist to make a quick buck. Indeed many mobile sites on which our ads were shown serve primarily adult content; the abundance of these sites mirrors the state of the web two decades ago when banner ads first started appearing on similar sites. The two large cluster are different adult entertainment networks, one hosted in Turkey, and one in Denmark. We do not investigate these clusters.
Ant-smasher and similar games: At least 2% of clicks
on control ads came from smartphone games that all require the user to tap the
screen close to where the ad is displayed. One such example is the
Ant-smasher iPhone app where ants randomly walk around the screen up to
(and under) where the ad is shown in the game, and the user must tap the ant
before it disappears from the screen to progress in the game. We installed the
games directing the most traffic and confirmed the following modus operandi.
How it works:
Discussion: The core issue here is the advertiser being charged despite the user not spending any time on the landing page. It is hard for an ad network to know how long the user spent on the advertiser’s site. If it relied on the advertiser to get this information, the advertiser could easily lie to get a discount. Solving this without modifying the browser, and without hurting the user experience is a non-trivial problem.
One mitigating approach would be to audit games and apps that trick users into mistapping on the ad. Doing so would likely spark an arms race for apps intentionally exploiting this loop-hole, but would at least protect advertisers from apps accidentally triggering this. Unfortunately, ad networks are making it harder for advertisers and independent third-parties to identify bad apps. During the course of our study, one major mobile advertising network stopped sending the application ID in the HTTP Referer.
Who made money: The app made money from the ad network.
waptrick.com and other sites: There is a sizable number of WAP phones (phones with a limited browser that access the web via a WAP proxy) that mobile ads are shown to. Nearly 42.1% of traffic on our mobile control ads are from these sources. We loaded a number of implicated sites with our browser’s user-agent set to that of a WAP browser.
How it works:
Discussion: Proxies are the biggest hurdle in tracking down bad WAP sites that confuse the user. As mentioned, less than 36% of our clicks had the HTTP Referer we need to track it back to the originating website and confirm that it intermixed ads with content. While one might wish for legacy phones to die out, it is unlikely to do so in developing countries in the near future. Advertisers wishing to reach a global market will have to contend with click-spam originating through these vectors.
Who made money: The WAP website made money from the ad network. For websites that have arrangements with proxies, the proxy operator potentially made some fraction of that money.
Investigating 26% of clicks on our control ads, we find the five classes of invalid clicks discussed above. We believe there are more classes of dubious traffic lurking in our data, and are investigating more automated means of reconstructing the attacks. In any event, we find that click-spam is by no means a solved problem.
We also find that while there is a policy component to many of the case-studies we presented, there is also an associated technology (and research) component to proactively discover attacks.
Mobile is a particularly tricky case where much of the telemetry needed for detecting click-spam doesn’t exist. Given the large role mobile advertising is expected to play in the coming future, research in this space is both important and timely.
Related work falls into three distinct categories.
Measuring Traffic Quality: There is surprisingly little past work in systematically measuring the quality of click traffic. [26] develops a learning algorithm for estimating the true CTR of an ad in the presence of click-spam. [41] measures traffic from bulk traffic providers and finds some providers to be qualitatively worse than ad networks. Startups including Adometry, Visual IQ and ClearSaleing that claim to be able to estimate click-spam rates provide no transparency into the specifics of their methods; furthermore, these approaches apply only at the granularity of entire ad networks, which we found is insufficient information for advertisers. Our click-spam estimation approach, which is grounded in our Bayesian framework and validated through extensive measurements, is the first principled approach an advertiser can independently apply at the granularity of his individual ads.
Documenting Click-Spam: The second category of related work is a snapshot-in-time of click-spam attacks, much like the case-studies presented in this paper. Daswani et. al. [19] give a good introduction to online advertising, pricing models, and online advertising fraud. Botnets like Clickbot.A [20], TDL-4[36] and other botnets [34] have been used for click fraud. More recent work describes fraud in ad exchanges [38]. Individual advertisers, and security researchers have documented many more attacks in blog posts and white-papers [13, 8, 10]. Each of these has been an ad-hoc targeted investigation given a specific publisher or attack vector. Our generic clustering and heavy-hitter detection approach instead starts from raw click logs to automatically identify (and prioritize) potential publishers/attack vectors for targeted investigations.
Mitigating Click-Spam: The third category of related work aims to identify individual clicks as click-spam so they can be discounted. Bluff Ads [25], on which we base our control ad design, are ads with unrelated targeting information (e.g., dog food ads for cat lovers). Clicks on Bluff ads are assumed to be click-spam, which the ad network should discount. While we subscribe to this assumption, we differ in how such ads should be used. [25] suggests blacklisting users that have above-threshold clicks on bluff ads. There are two problems. First, this only applies to click-spam driven by malware. In the non-malware scenarios we discovered, blacklisting the user serves little purpose since the bad publishers get a steady stream of unwitting users (false-negatives for Bluff ads); furthermore, the legitimate clicks of blacklisted users on good publishers would also get discounted (false-positives). The second problem is that even for click-spam driven by malware, it wouldn’t work. The malware we analyzed performs one click per day. If Bluff Ads were to be shown 1% of the time, it would take on the order of a 100 days to blacklist a user. The cost to the ad network would be 1% of their revenue (hundreds of millions of dollars for reputed networks), which would be unacceptably high. We use control ads in a different way; we use it sparingly to collect data ($1000 represents a negligible fraction of ad network revenue), from which we then extract click-spam signatures that apply more broadly.
Other approaches to mitigating click-spam include SbotMiner [40], Sleuth [33] and Detectives [32]. SbotMiner tries to identify bot activity by using KL-divergence to detect change in query distributions, followed by pruning of false positives due to flash crowds, by leveraging heterogenity for genuine users. Sleuth uncovers single publisher fraud by finding correlation in multi-dimensional data; however, they claim that the technique is suitable only when the botnet uses tens of hundreds of IP addresses. Detectives detects coalition hit inflation attacks by their similarity seeker algorithm; it discovers coalitions made by pairs of fraudsters, which is then enhanced in [31] by finding groups of fraudsters. All these approaches apply only to botnet and malware driven click-spam, which is dwarfed by other sources of click-spam in our data.
Premium Clicks [27], access control gadgets (ACG) [37] and CDN fraud prevention [30] focus on mitigation strategies that go beyond botnets. Premium clicks employs economic disincentives that devalue clicks from non-gold-standard users. ACGs ensure authentic UI interactions by users clicking a link. CDN fraud prevention proposes a heavy-weight challenge-response protocol for publisher-payee CDN models. While the first assumes an alternate ad economy, the second and third (applied to ad networks) require re-architecting the browser, or the ad network infrastructure. None of these approaches apply to click-spam in existing ad networks.
Focusing squarely on existing ad networks, Camelot [28] is Google’s click-fraud penetration system. It can test the susceptibility of the network to known click-spam signatures, but does not itself detect new signatures. [39] describes the invalid click detection system inside Google, without identifying the specific heuristics that are used to identify invalid clicks. No heuristic is perfect. Our data shows click-spam is still an open problem despite these deployed systems.
In this paper, we take a systematic look at click-spam. We propose the first methodology for advertisers to independently measure click-spam rates on their ads. We also develop an automated methodology for ad networks to proactively fingerprint different simultaneous click-spam attacks. We validate both methodologies using data from major ad networks. We then conduct a large-scale measurement study of click-spam across ten major ad networks and four types of ads. In the process, we identify and perform in-depth analysis on seven ongoing click-spam attacks not currently caught by major ad networks. We conclude that even for the largest ad networks, click-spam is a serious problem, and is especially rampant in the mobile advertising context. Given the evolving nature of click-spam, we believe that click-spam is an open problem that requires a concerted effort from the research community to tackle. To this end we have publicly released the data gathered for this paper to aid other researchers in the design of novel click-spam defense techniques.
We’d like to thank Jigar Mody, Matt Graham, our shepherd Kirill Levchenko, and our anonymous reviewers. This paper is much improved thanks to their valuable feedback and suggestions.
This document was translated from LATEX by HEVEA.